 火星网校
火星网校
北大机器人当上亚运志愿者,全靠学生把多模态大模型结合具身智能
发布时间:2023-11-28 14:54:20 浏览量:121次
论机器人想在杭州当志愿者有多拼
北大 把投稿扔向 凹非寺
|
亚运会导游,原来背后离不开北大学生团队!
且看这个智能导游,它可不是一般人:
外观看上去像一辆小车,四个轮子在地面上快速灵活移动。

上面安装了机械臂,配有摄像头及语音等交互设施,使其能够对周围环境和需要执行的任务进行识别与理解。

据悉,这名导游机器人系统由北大计算机学院HMI团队研发,它结合了多模态大模型和具身智能。
在亚运会期间,它为视障人士提供引领和导航等帮助,并可解析视障人士的需求并完成相应任务,如帮助他们捡拾掉落的物品等。
具身智能,搭载多模态大模型那种
那么,这位具身智能导游是怎么炼成的?
在研究员仉尚航的指导和支持下,北大学生们形成了一种创新路径,即设计感知生成一体化的多模态大模型,以实现对各种视觉场景的精准感知与理解,并生成准确丰富的语言描述。
之所以这样设计,是因为这个导游最初就设计定位为服务残障人士、老年人、少数民族等——当前的技术落点,还没有完全解决他们的需求。
“少数民族的观众可能面临语言障碍,而残疾人士可能需要更多的辅助工具或特别的服务,以便更好地享受比赛。”团队成员、北大学生庄棨宁表示,多模态大模型是课题组的重点研究方向,于是一个把多模态大模型和具身智能结合起来,研发一个专门服务残障人士观赛的AI系统的想法,诞生了。
于是,多模态爱心助手亮相亚运会。

多模态爱心助手所搭载的系统,基于团队自研的感知生成一体化通用多模态大模型。
该系统集成了大模型的泛化感知能力和涌现能力。
同时,在爱心助手身上,多模态大模型和具身智能结合了起来,为机器人赋予更加智能的大脑,使其可以将人类复杂需求转化为具体行动指令。
它能做的事情,体现出一体化处理能力,包括:
- 场景感知,能够识别图像中的特定目标或特征;
- 场景解析,能够为图像生成描述性文本;
- 行为决策与规划,具备基于图像和文本信息进行决策和规划的能力。
考虑到机器人会面对不同场景,需要具备快速适应新场景的泛化能力,团队设计了基于端云协作的大小模型协同高效微调,提升模型的泛化性,使其可以持续适应不同的场景。
举个例子。
如果有运动员用户说“我渴了”,机器人听到这句话后,完成转身拿水——递到用户手中,过程看似简单,实际上涉及了一系列子任务:
- 首先捕捉“我渴了”这句语音信号,然后通过语音识别技术,转换为文字;
- 理解“我渴了”这句话的含义,即用户现在需要水;
- 通过良好的感知能力,利用CV技术,识别、定位瓶装水;
- 规划来到瓶装水面前的路线,涉及路径规划算法;
- 控制自身动作,根据路径规划,来到水面前;
- 准确抓住瓶装水,涉及视觉检测、机器人控制系统和抓取的相关技术;
- 规划返回路径,并控制自身动作,将水送到说话者的手中。

上述的每一个子任务,都需要大量的研究和工程实践。
不仅如此,机器人还需要能够处理在训练数据中未曾出现过的新情况,也就是说,模型需要具有强大的泛化能力,能够在新的、未知的环境中有效地工作。
为了提升机器人在开放环境下的持续性泛化能力,团队构建了一个端云协作的持续学习系统。
这一系统的设计旨在兼顾终端计算的个性化、隐私保护和低通信成本等优势,同时也充分利用云端计算的大规模计算资源、大量标注数据以及卓越的泛化能力。
还研发亚运会赛事解说AI系统
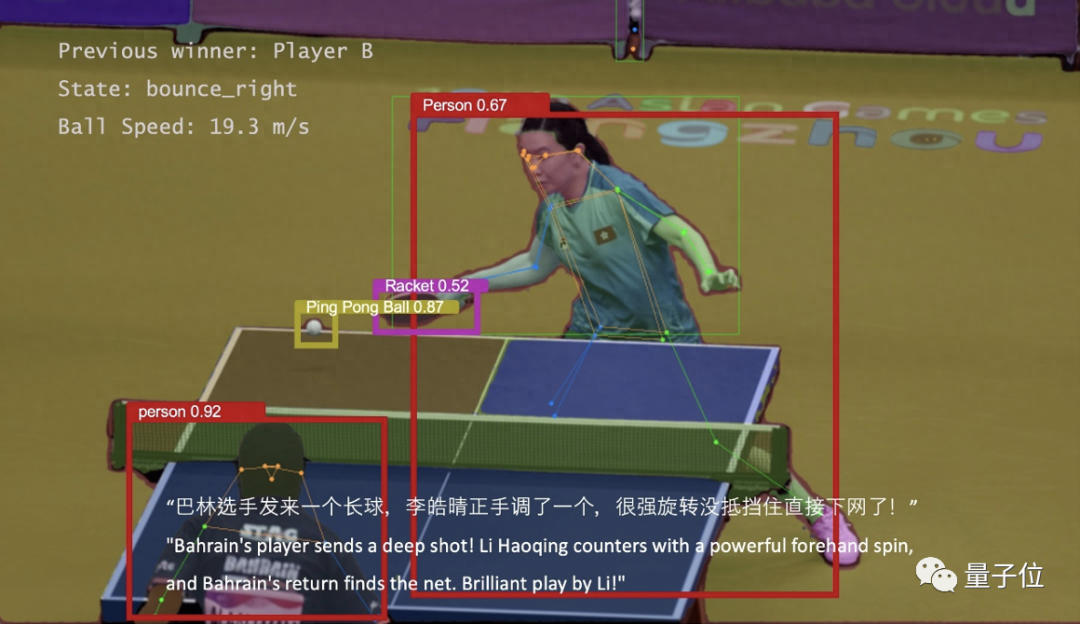
据悉,杭州亚运会的多模态多语种视频解说系统,也出自这个团队之手。
基于多模态大模型,团队通过自研的X-Accessory一体化大模型工具链,设计了多模态多语种视频解说系统,在亚运会期间用于乒乓球、跆拳道、跳水、体操等赛事。
这个解说系统的特点在于,不仅能够理解和分析正在进行的比赛,生成实时的解说内容,还可以根据观众的喜好提供个性化的解说服务,包括将解说内容翻译成多种语言,包括维吾尔语、阿拉伯语等。
除了应用在本次亚运会,团队在大模型方面还有许多其他成果。
“多模态大模型是我们组研究的核心,目前也取得了一定的成果。”北京大学计算机学院博士后王冠群介绍,“除了这次自研的感知生成一体化通用多模态大模型、大小模型协同训练与部署,我们还关注多模态生成式大模型Agent设计、大模型记忆机制设计、面向多场景的智能医疗多模态大模型集群、通用大模型适配器等。”
就拿团队进行的多模态生成式大模型Agent设计来说。
单模态模型无法有效地结合视觉、听觉和文本等多种模态信息,这种局限性在复杂的实际场景,如虚拟助手、机器人交互和智慧城市中,可能导致效果并不理想。
因此,团队开发了一种多模态生成式大模型Agent,将各种模态的优点结合起来,例如视觉的细节捕捉能力、听觉的时序特性和文本的结构化知识。
这样的综合性设计,将有助于推动生成式模型向更加实用和高效的方向发展,满足未来多种复杂应用场景的需求。
在更复杂的应用场景,团队还研究过面向多场景的智能医疗多模态大模型集群。
他们设计和实现了一组智能医疗多模态大模型集群,包括面向患者的个性化医疗知识问答多模态时序大模型、面向医生的临床影像报告生成多模态大模型和面向导诊场景的检索增强大语言模型。
这样一来,能使大模型技术适配临床场景,满足患者-医生-医院多方诉求,解决行业痛点,推动大模型在医疗领域的落地应用。

△杭州亚运会期间科研团队合影(第一排左起:张雨泽、庄棨宁、谢爱丽、仉尚航、张融宇、罗峪霖、王振宇;第二排左起:侯沂、戴鸿铭、王昊、李忱轩、张启哲、刘家铭、王冠群)




热门课程推荐

热门资讯
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
2. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
3. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
4. AI显卡绘画排行榜:4090无悬念,最具性价比出人意料
在AI绘图领域,Stable Diffusion的显卡绘图性能备受关注。本文整理了Stable Diffusion显卡的硬件要求和性能表现,以及2023年3月显卡AI绘图效率排行榜和性价比排行榜。欢迎查看最新的AI显卡算力排行榜。
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
7. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
8. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
AI技术的快速发展为各行各业带来了许多创新应用,其中之一就是AI小说生成视频。这种技术利用人工智能算法和语言模型,将文本转化为视频剧情,加上配图、...
最新文章
