 火星网校
火星网校
Sora之后,OpenAI Lilian Weng撰文教你从头设计视频生成扩散模型
发布时间:2024-05-18 12:34:15 浏览量:251次
选自Lil’Log
作者:Lilian Weng
机器之心编译
编辑:Panda
过去几年来,扩散模型强大的图像合成能力已经得到充分证明。研究社区现在正在攻克一个更困难的任务:视频生成。近日,安全系统(Safety Systems)负责人 Lilian Weng 写了一篇关于视频生成的扩散模型的博客。


视频生成任务本身是图像合成的超集,因为图像就是单帧视频。视频合成的难度要大得多。
如果你想了解扩散模型在图像生成方面的应用,可参读本文作者 Lilian Weng 之前发布的博文《What are Diffusion Models?》
从头建模视频生成
首先,我们先来看看如何从头设计和训练扩散视频模型,也就是说不使用已经预训练好的图像生成器。

模型架构:3D U-Net 和 DiT
类似于图扩散模型,U-Net 和 Transformer 依然是常用的架构选择。VDM 采用了标准的扩散模型设置。
- 处理空间:原本和 2D U-net 中一样的 2D 卷积层会被扩展成仅针对空间的 3D 卷积。
- 处理时间:每个空间注意力模块之后会添加一个时间注意力模块。
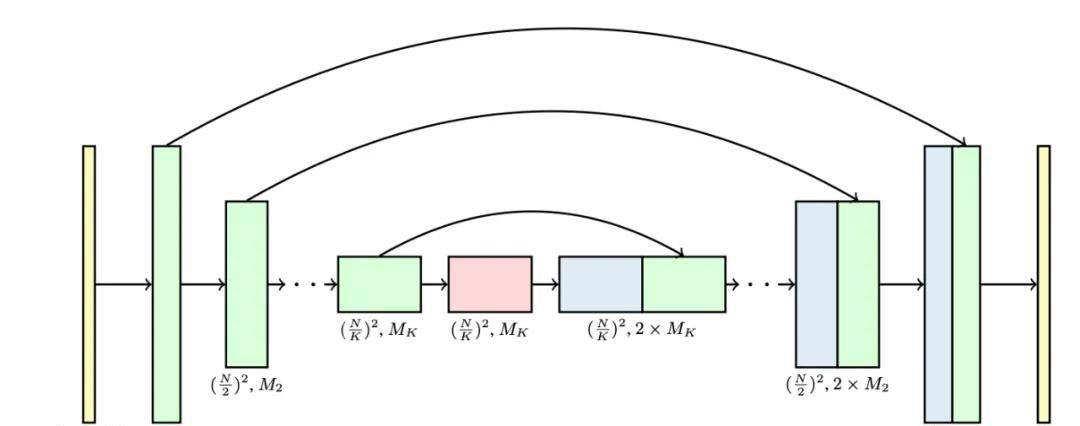
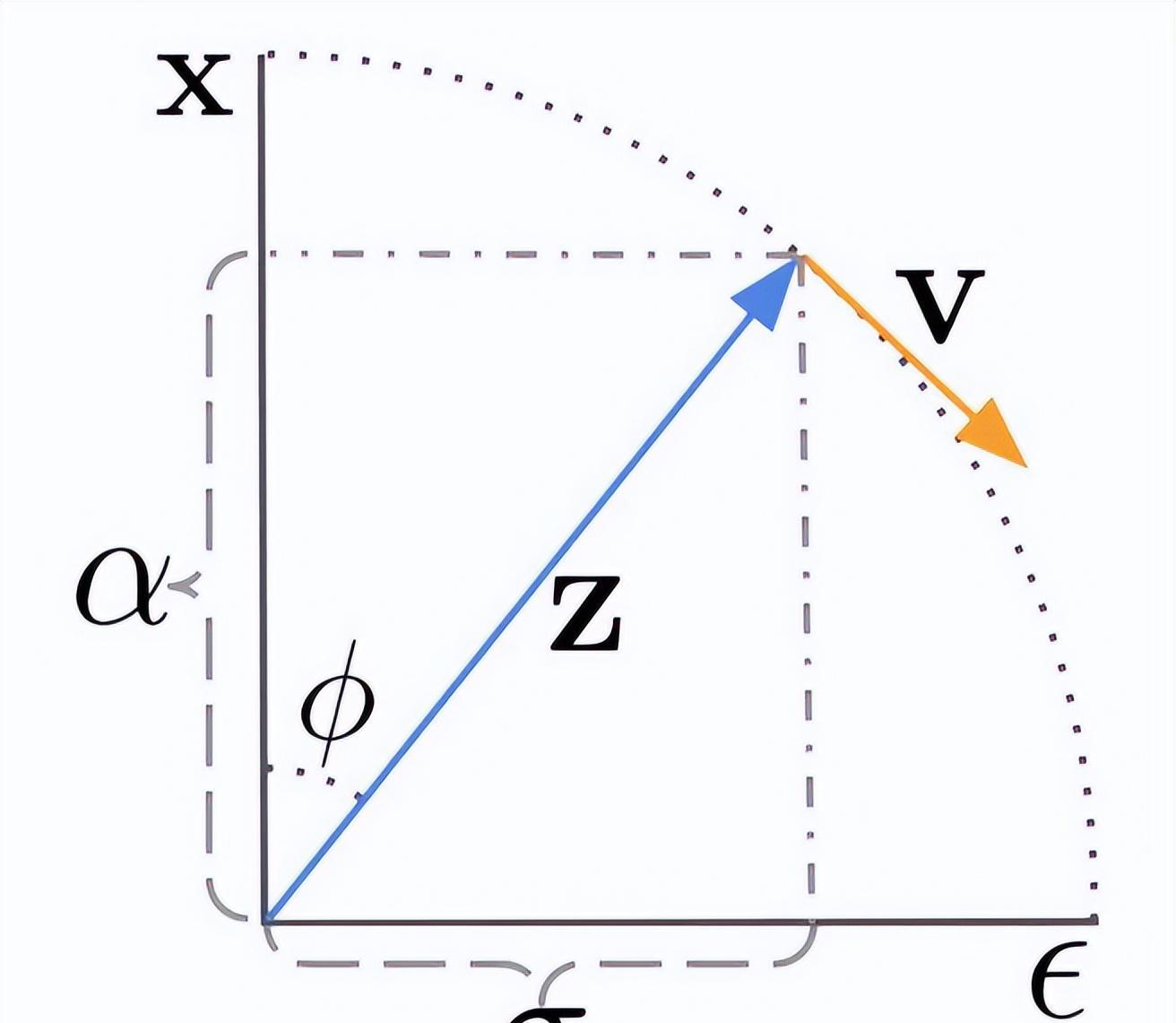
图 2:3D U-net 架构。
基础去噪模型使用共享的参数同时在所有帧上执行空间操作,时间层将各帧的激活混合起来,以更好地实现时间一致性。
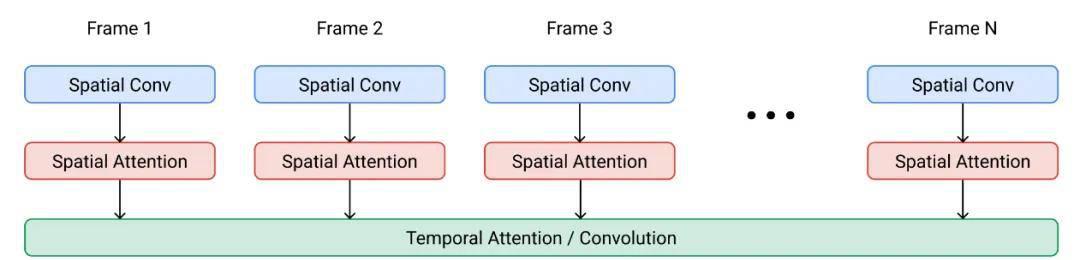
图 4:Imagen Video 扩散模型中一个空间 - 时间可分离模块的架构。
VDM 还应用了渐进式蒸馏来加速采样,每次蒸馏迭代都可以将所需的采样步骤减少一半。
调整图像模型来生成视频
在扩散视频建模方面,另一种重要方法是通过插入时间层来「扩增」预训练的图扩散模型。
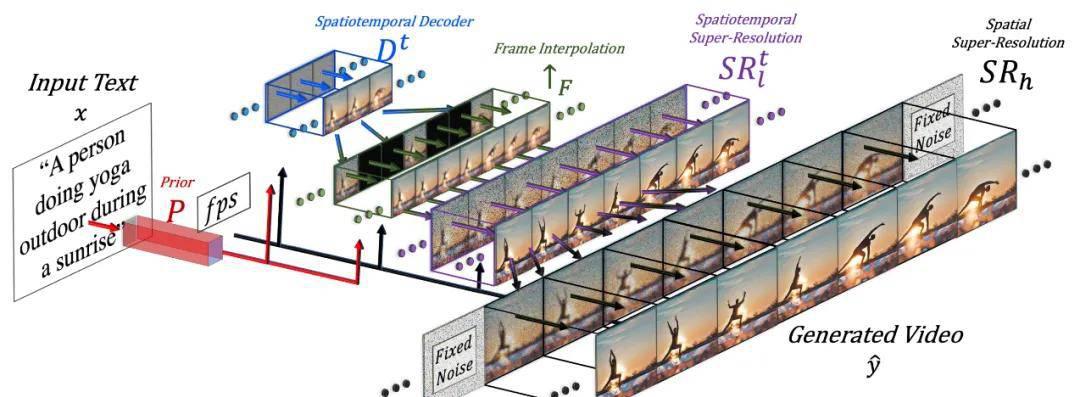
图 6:Make-A-Video 工作流程示意图。
最终的视频推理方案的数学形式
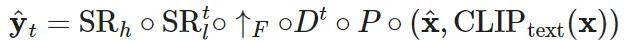

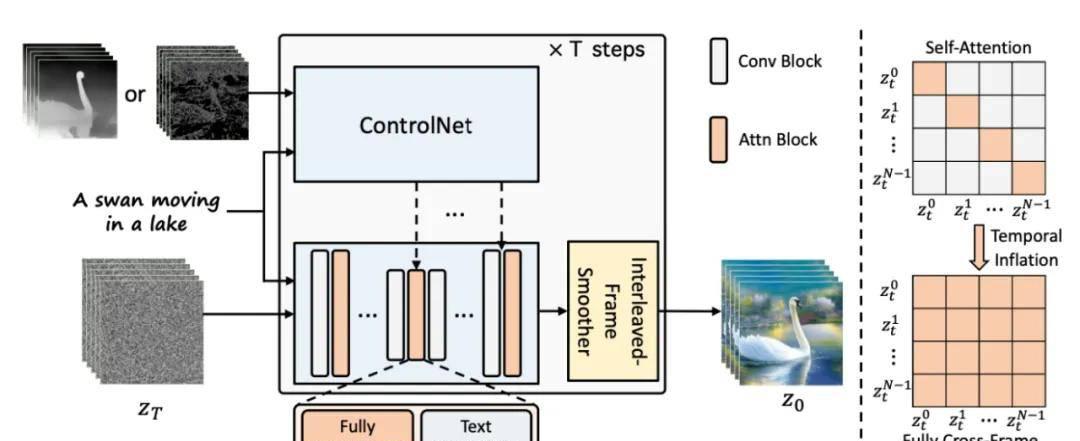
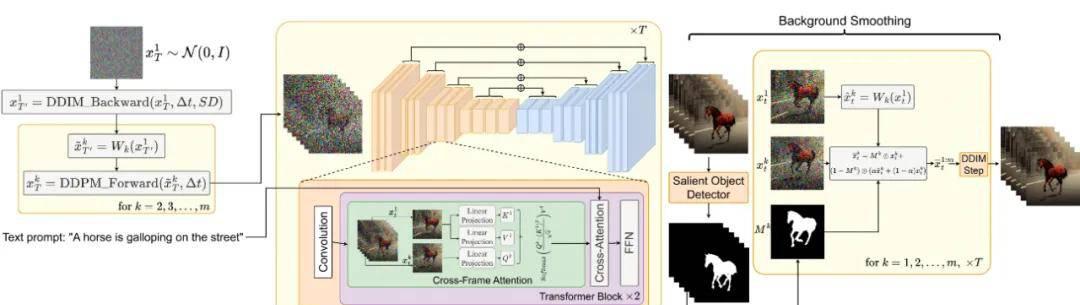
无训练适应
也有可能不使用任何训练就让预训练的图模型输出视频,这多少有点让人惊讶。
如果我们直接简单地随机采样一个隐含代码的序列,然后用解码出来的对应图像构建一段视频,那么无法保证物体和语义在时间上的一致性。




热门课程推荐

热门资讯
-
1. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
4. 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
人人都可以动手制作AI视频! 打开网址https://pixverse.ai/,用邮箱注册后,点击右上角Create,就可以开始创作了。 PixVerse目前有文案生成视频,和图片生...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
6. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
8. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
9. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
10. Logo Diffusion——基于sd绘画模型的AI LOGO 生成器
这下LOGO设计彻底不用求人了。接下来详细演示一遍操作流程首先进入Logo D... 想学习更多AI技能,比如说关于怎么样利用AI来提高生产效率、还能做什么AI...
最新文章
