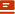 火星网校
火星网校
北大&腾讯打造多模态15边形战士!语言作“纽带”,拳打脚踢各模态,超越Imagebind
发布时间:2023-11-12 13:24:27 浏览量:113次
还自建首个有深度和红外的大规模多模态数据集
AI4Happiness 投稿
|
北大联合腾讯打造了一个多模态15边形战士!
以语言为中心,“拳打脚踢”视频、音频、深度、红外理解等各模态。
具体来说,研究人员提出了一个叫做LanguageBind的多模态预训练框架。
用语言作为与其它模态之间的纽带,冻结语言编码器,然后用对比学习方法,将各个模态映射到一个共享的特征空间,实现多模态数据的语义对齐。
使用这种方法,模型在5个数据集上的性能拿下新SOTA,在15个zero-shot检索等任务中取得了显著的性能提升,全面超越ImageBind、OpenCLIP。

将各模态与语言绑定
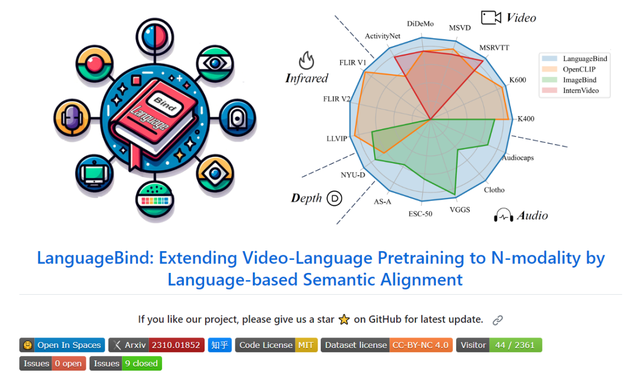
LanguageBind包含三个部分:
多模态编码器(Multi-modal Encoders),语言编码器(Language Encoder),以及多模态联合学习(Multi-modal Joint Learning)。
先来看多模态编码器部分。
除了语言之外的其它模态,研究人员使用24层、1024维的视觉Transformer,具有14的Patch大小。编码器是从OpenCLIP-large初始化的。
深度和红外被视为RGB图像,在通道维度上复制3次与RGB图像对齐。
按照ImageBind的方式,音频数据被转换为持续10秒(128个mel-bins)的频谱图,并进行重复和填充。
- Patch masking
为了解决在编码器中处理所有Token的低效问题,研究人员将图像分成补丁,并通过Mask获取一小部分图片序列,按照MAE的方法进行。
- LoRA fine-tuning
同时使用LoRA技术来加速微调。对于具有权重矩阵W0∈Rd×k的模态编码器,在学习新的权重矩阵BA时,保持权重矩阵W0不变。
- Modality extending
将LanguageBind方法扩展到多个(N个)模态的第一步是将数据处理成令牌序列。随后,参数将从OpenCLIP进行初始化。然后通过令牌屏蔽和LoRA微调来训练不同模态的编码器,同时保持语言编码器冻结。最后,将该模态与语言特征空间对齐。
再来看看语言编码器以及多模态联合学习部分。
对于语言编码器,研究人员使用了一个12层的transformer模型,维度为768,初始化来源于OpenCLIP。
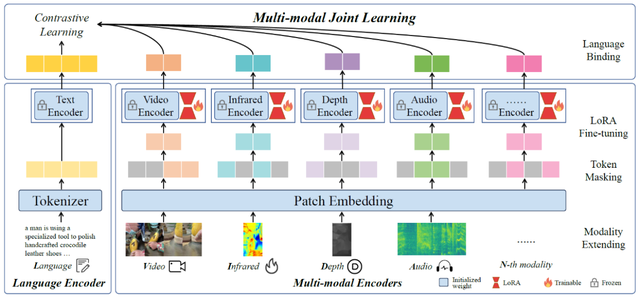
对于给定的文本,他们首先使用BPE分词器将单词分割成相对常见的子词。每个子词对应一个唯一的标记,这些标记在一个词嵌入层内嵌入。最终,这些标记被语言编码器编码,以获得文本对数:
其中L表示序列的长度。为了确保跨不同模态的对齐,研究人员采用了对比学习原则。
这种方法的目标是增加配对数据的相似性,将它们带到相同的语义空间,同时减小不配对数据的相似性。研究人员利用对比学习将各个模态与语言绑定在一起。
构建高质量数据集
此外,研究人员还创建了一个名为“VIDAL-10M”的高质量数据集,其中包含1000万个具有对齐视频-语言、红外-语言、深度-语言、音频-语言的数据对,是第一个具有深度和红外模态的大规模视频多模态数据集。

数据集构建方法如下:

△VIDAL-10M 构建框架
第一步是生成搜索词数据库,这个过程中,研究人员设计了一种独特的搜索词获取策略,利用来自各种视觉任务数据集的文本数据,包括标签和标题,以构建具有丰富视觉概念和多样性的视频数据集。
第二步是从互联网收集相关视频和音频,并进行一系列过滤处理,以确保数据集的质量和准确性。
这个过程中,研究人员使用了多种过滤方法,包括基于文本的过滤、基于视觉与音频的过滤,以确保数据集中的视频和音频与搜索词相关且质量高。
第三步是进行红外和深度模态生成,以及多视角文本生成和增强。
在空间信息增强方面,研究人员采用了OFA模型生成多个关键帧描述,以提升视频内容的空间表达质量。
同时,在时间信息增强方面,将视频内容、标题以及Hashtag标签输入到mPLUG-owl模型中,以获取更为精炼和丰富的时间维度描述。
最后,研究人员运用ChatGPT模型对文本描述进行进一步细化和增强。
综合而言,多视角文本增强涵盖了标题、标签、关键帧描述以及视频描述等多个组成部分,为视频内容提供了全面且详尽的描述。
多个测试拿下SOTA
在测试阶段,大量的实验验证了VIDAL-10M数据集和LanguageBind方法的有效性,在视频、音频以及其它模态理解任务中取得了显著的性能。

LanguageBind在四个数据集上都性能拿下SOTA。
在MSR-VTT上比InterVideo方法高出1.9%,在MSVD上比 InterVideo高出 8.8%,在DiDeMo上比InterVideo高出 6.3%,在ActivityNet上比InterVideo高出 4.4%。
值得注意的是,InterVideo采用了更广泛的训练数据,正表明LanguageBind的有效性。
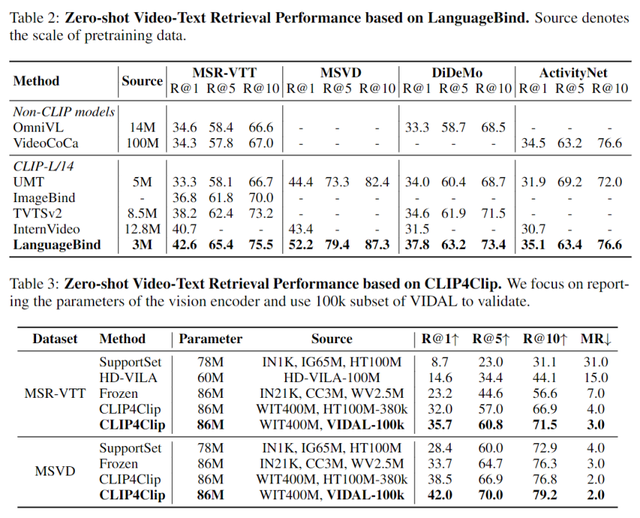
△Zero-Shot视频-文本检索结果
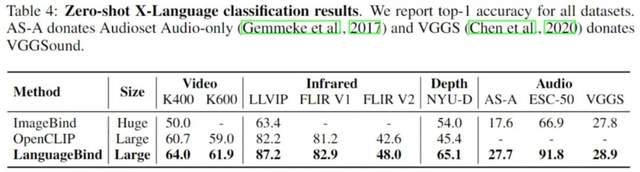
视频-语言、红外-语言、深度-语言和音频-语言Zero-Shot分类,在所有数据集上的准确率均优于ImageBind、OpenCLIP:
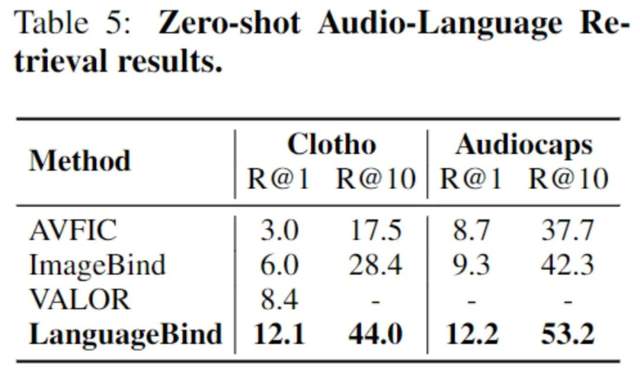
Zero-Shot音频-语言检索性能同样优越:
论文链接:https://arxiv.org/pdf/2310.01852.pdf




热门课程推荐

热门资讯
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
2. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
3. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
4. AI显卡绘画排行榜:4090无悬念,最具性价比出人意料
在AI绘图领域,Stable Diffusion的显卡绘图性能备受关注。本文整理了Stable Diffusion显卡的硬件要求和性能表现,以及2023年3月显卡AI绘图效率排行榜和性价比排行榜。欢迎查看最新的AI显卡算力排行榜。
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
7. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
8. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
AI技术的快速发展为各行各业带来了许多创新应用,其中之一就是AI小说生成视频。这种技术利用人工智能算法和语言模型,将文本转化为视频剧情,加上配图、...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
最新文章
