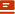 火星网校
火星网校
从个人到集体,迈向更多元的3D人体动作生成技术
发布时间:2024-06-27 13:09:22 浏览量:99次

近期关注的3D人体动作生成技术受到越来越多的关注,探索更加全面且多样化的动作生成方法。新技术基于GAN和Transformer框架,不仅支持单人动作生成,还能轻松拓展到多人动作生成。通过构建GTA Combat数据集,填补了现有复杂场景交互数据集的不足。

ActFormer框架支持多种类型的人体动作表征,实现单人/多人动作生成
简介
3D人体动作生成是计算机视觉和图形学中的热门话题,特别是近期的文本描述生成人体动作研究更受关注。现有工作局限于某些人体表征,忽略多人动作生成,因此需要更通用的框架支持多种人体动作表征和单人/多人动作生成。
具体方法
Actformer框架图
Actformer可以生成含有多个个体的人体动作序列,支持骨架坐标或SMPL参数模型表示。单人动作生成需要考虑时序连贯性,采用高斯过程隐式先验和Transformer生成网络。
多人动作生成通过交互Transformer和时序Transformer结构实现,共享隐式表征,保证生成结果同步。
生成过程采用生成对抗训练,通过条件Wasserstein GAN损失函数训练。实验中,考虑了人的全局位移并应用了数据增强方案。
GTA Combat数据集
为弥补多人交互数据集的缺乏,基于GTA-V游戏引擎合成了多人打架数据集,保证交互真实感和丰富随机性。

GTA Combat数据集概况
实验
在多个数据集上进行实验,证明了算法的有效性和泛化性。评测使用动作识别准确率和FID分数作为量化指标,结果表明算法效果优异。

单人动作生成结果对比

多人动作生成结果对比
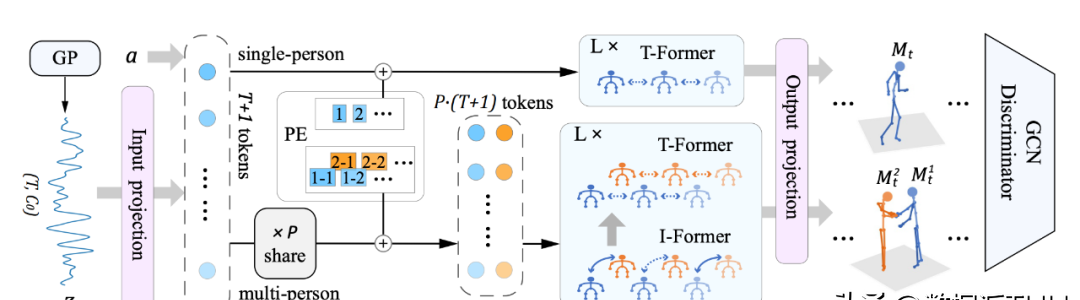
NTU-1P上的网络模块消融实验
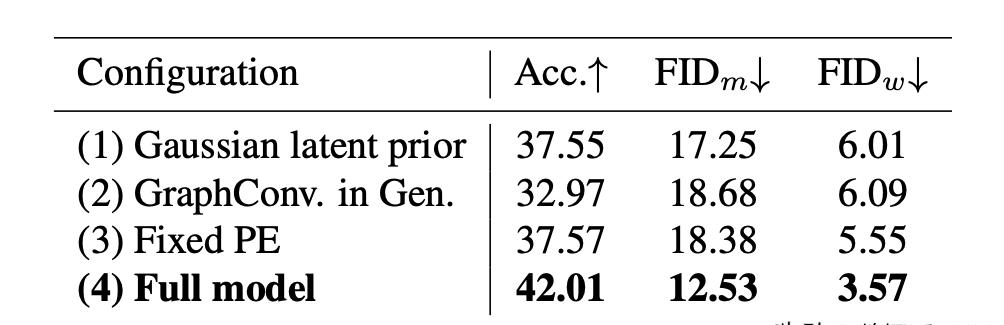
NTU-2P上的网络模块消融实验

多人交互编码消融实验
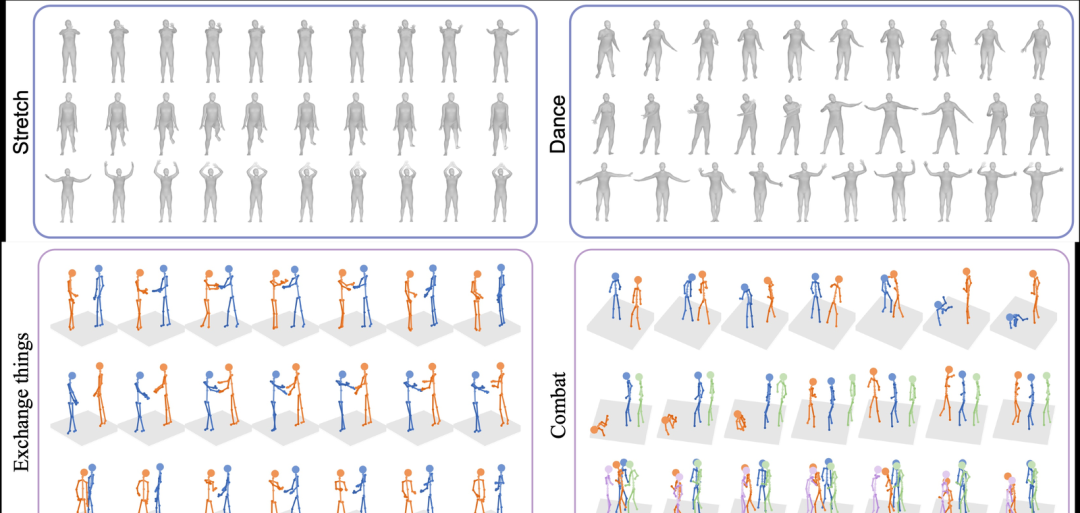
可视化结果
结论
继续关注3D人体动作生成领域的发展,新技术展示了巨大的潜力。欢迎加入我们共同探索人体动作/交互的理解与生成领域。
参考文献:
- Guo, Chuan, et al. “Action2motion: Conditioned generation of 3d human motions.” Proceedings of the 28th ACM International Conference on Multimedia. 2020.
- Petrovich, Mathis, Michael J. Black, and Gül Varol. “Action-conditioned 3D human motion synthesis with transformer VAE.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
- Yan, Sijie, et al. “Convolutional sequence generation for skeleton-based action synthesis.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
- Yan, Sijie, Yuanjun Xiong, and Dahua Lin. “Spatial temporal graph convolutional networks for skeleton-based action recognition.” Proceedings of the AAAI conference on artificial intelligence. Vol. 32. No. 1. 2018.
- Loper, Matthew, et al. “SMPL: A skinned multi-person linear model.” ACM transactions on graphics (TOG) 34.6 (2015): 1-16.




热门课程推荐

热门资讯
-
想了解动画制作和影视特效的区别吗?本文将带您深入探讨动画制作和影视特效之间的关系,帮助你更好地理解这两者的差异。
-
剪映专业版新增全局预览缩放功能,可以轻松放大或缩小时间轨道。学习如何使用时间线缩放功能,提升剪辑效率。
-
3. 豆瓣8.3《铁皮鼓》|电影符号学背后的视觉盛宴、社会隐喻主题
文|悦儿(叮咚,好电影来了!)《铁皮鼓》是施隆多夫最具代表性的作品,影片于... 分析影片的社会隐喻主题;以及对于普通观众来说,它又带给我们哪些现实启发...
-
想知道快影、剪映、快剪辑这三款软件哪个更适合小白?看看这篇对比评测,带你了解这三款软件的功能和特点,快速选择适合自己的视频剪辑软件。
-
5. 从宏观蒙太奇思维、中观叙事结构、微观剪辑手法解读《花样年华》
中观层面完成叙事结构、以及微观层面的剪辑手法,3个层次来解读下电影《花样年华》的蒙太奇魅力。一、 宏观层面:运用蒙太奇思维构建电影剧本雏形。蒙...
-
1、每个切点需要理由和动机 很剪辑师认为,赋予每一个切点动机是非常困难的。很多...
-
了解Blender和3ds Max之间的不同,哪个更适合您?快来看看这两款3D建模软件的特点和功能吧!
-
8. 哪家IT培训机构靠谱?传智播客和黑马程序员等7家机构盘点
想要了解哪些IT培训机构靠谱?训哥儿为你介绍了7家培训机构,从大机构到中小机构,带你了解各家机构的特色和亮点。
-
9. 从剪辑手法、物品隐喻、主题探讨深度解读《勺子杀人狂》的内涵
今天我要跟大家分享的是一部关于勺子的电影:《勺子杀人狂》。影片是Richa... 今天本文将从影片的剪辑手法、物品隐喻、主题探讨三个角度解读《勺子杀人...
-
15种电影剪辑/转场手法,让影片更吸引眼球!回顾电影中丰富多样的专场技巧,比如瞬间从一个场景中变换到空中... 现在是测试技术的时候了!以下是一些常见剪辑手法,让你观影过程更加华丽动人!
最新文章
