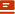 火星网校
火星网校
HuggingFace 联创发推:高质量微调数据集才是“卷”大模型的正确姿势
发布时间:2023-11-07 17:57:20 浏览量:116次
打造出一个新颖、高效且前沿的小型AI模型
最近,NLP大牛、HuggingFace联合创始人Thomas Wolf 发了一条推特,内容很长,讲了一个 “全球三大洲的人们公开合作,共同打造出一个新颖、高效且前沿的小型AI模型” 的故事。
故事是这样开始的,在几个月前,巴黎的一个新团队发布了他们首个模型:Mistral 7B,这个模型体积小巧但性能强劲,在基准测试中的表现超过了所有同类模型。
这还是个开源项目,意味着大家都可以在此基础上进行开发。
另一个研究模型微调和对齐的H4团队的两名成员,在Hugging Face举办的一次小聚中,他们边喝咖啡边讨论用斯坦福大学新发表的DPO方法对Mistral 7B这个模型进行微调的可能性,最后他们决定用已经构建好的代码库先来尝试下。
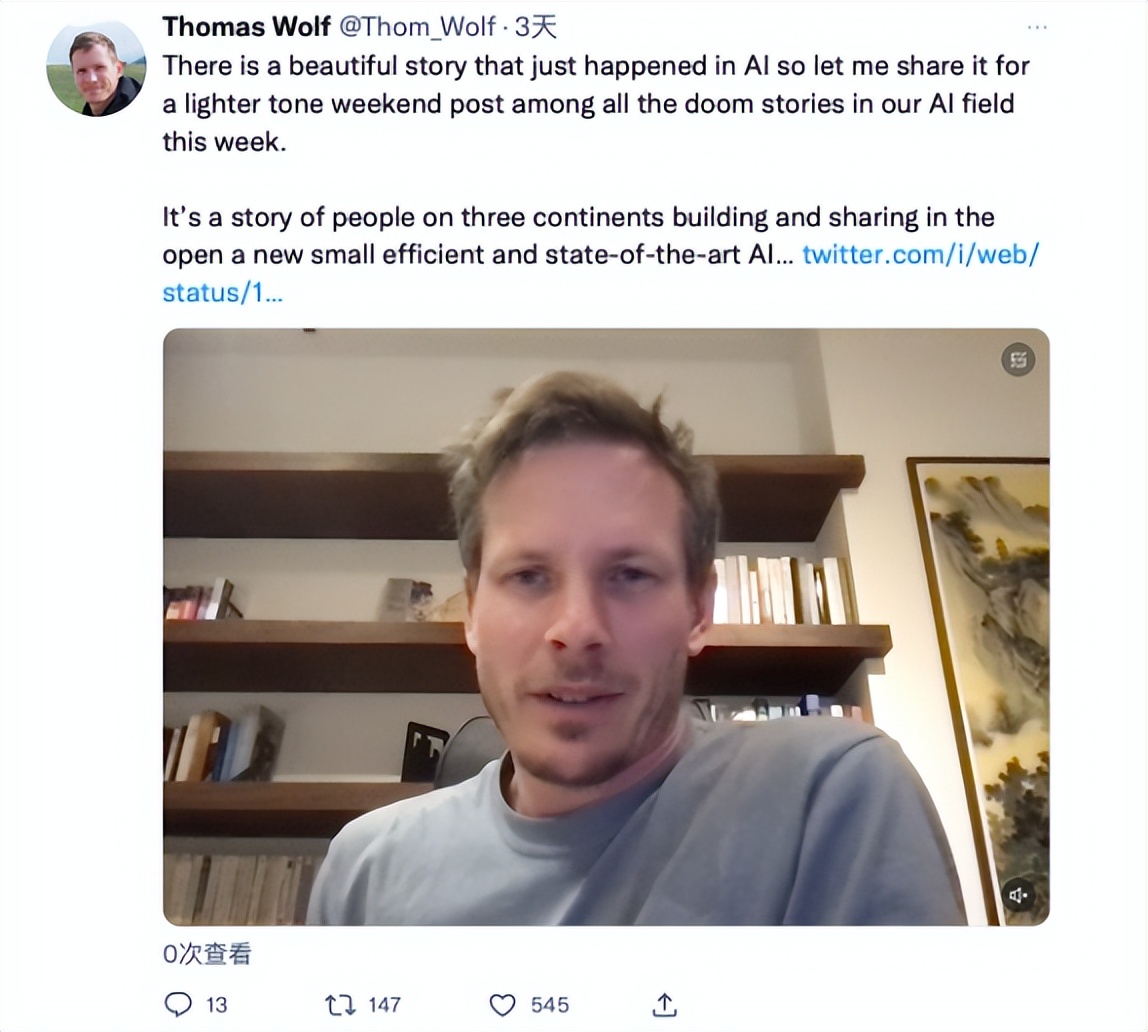
之后,他们在HF hub上找到了一些公开的数据集,包括由面壁智能和清华大学NLP共同支持的OpenBMB新近开源的两个大规模、高质量的微调数据集:UltraFeedback和UltraChat。
UltraFeedback,一个大规模、多样化、细粒度 的偏好数据集,包括 25万 条对话数据以及相应的偏好标注数据。在非社区标注的偏好数据集中,这一数据规模排在首位。并且,其中每条偏好标注均包含四个方面的细粒度得分与的详细文字说明。
UltraChat则是高质量的对话数据集,包含了 150 余万条多轮指令数据。调用多个 ChatGPT API 相互对话,从而生成多轮对话数据。
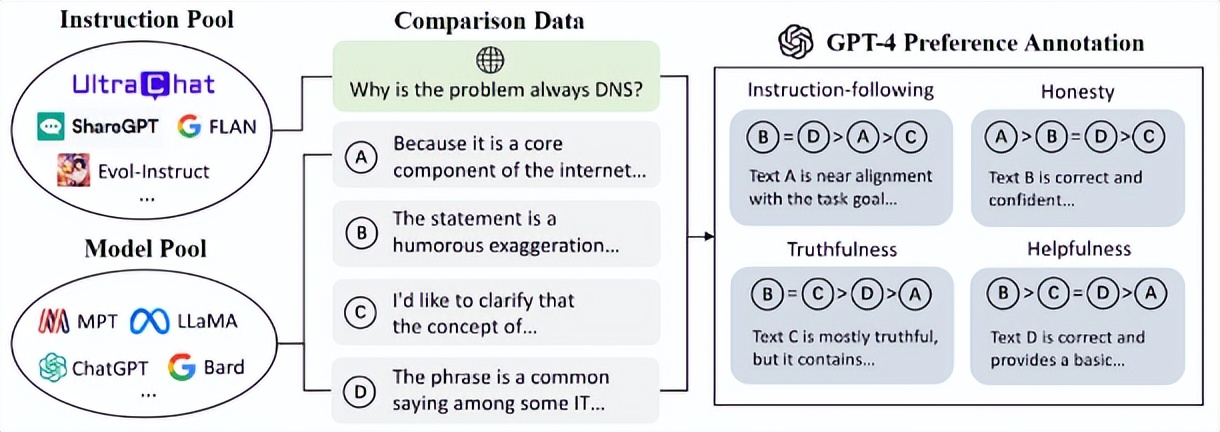
经过几轮实验证明,使用OpenBMB两个数据集训练出来的新模型非常强大,是H4团队 在伯克利和斯坦福的基准测试中见过的最强模型。
不久,这个名为“Zephyr”的模型、研究论文以及所有细节都向世界公开了,此后全球各地的公司开始应用这一模型。LlamaIndex,一个知名的数据框架和社区,分享了这个模型在实际用例基准测试中超乎预期的表现,与此同时,研究者和实践者们在Hugging Face hub上热烈讨论着这篇论文和相关工作。
Zephyr-7B性能 超越参数十倍之大的 LLaMA2-70B-Chat。
短短几周就创造了这个 开源神话。Thomas Wolf指出,这一切都得益于世界各地(欧洲、加利福尼亚、中国)对知识、模型、研究和数据集的开放获取,以及人们在AI上相互建设、相互借鉴,共同创造出真正有价值的高效开放模型的理念。
开源精神以自由和合作为信条,让人类再次联合起来重建通天巴别塔。开源旨在打破人为壁垒,通过开放透明的方式促进技术和知识的创新共享。对于个体或组织而言,拥抱开源则是一种强者心态。
值得一提的是,OpenBMB开源社区背后的国内领先的人工智能公司 面壁智能,一直联合清华大学NLP实验室为大模型事业做高质量的开源贡献的同时,一直深耕大模型底层的数据工作。
就拿此次被Zephyr-7B运用的UltraFeedback为例,UltraFeedback 从多个社区开源的指令数据集中收集了约 6 万条指令。基于这些指令,UltraFeedback 从 17 种不同架构、参数量、训练数据的模型中随机选取 4 种不同模型,为每条指令生成4种有区分度的回复,极大地提升了指令和模型的多样性。
基于 UltraFeedback,团队还训练了UltraRM、UltraCM两个模型来进一步辅助模型评测和模型反馈学习。
在大家都在卷模型参数时,一个基于高质量数据集的7B模型就打败了参数十倍之大的 LLaMA2-70B-Chat。这说明了什么?
说明,底层的数据工作才是最稀缺的和有时间价值的,这或许是各家各派大模型在百模大战中的突破口之一。




热门课程推荐

热门资讯
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
2. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
3. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
4. AI显卡绘画排行榜:4090无悬念,最具性价比出人意料
在AI绘图领域,Stable Diffusion的显卡绘图性能备受关注。本文整理了Stable Diffusion显卡的硬件要求和性能表现,以及2023年3月显卡AI绘图效率排行榜和性价比排行榜。欢迎查看最新的AI显卡算力排行榜。
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
7. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
8. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
AI技术的快速发展为各行各业带来了许多创新应用,其中之一就是AI小说生成视频。这种技术利用人工智能算法和语言模型,将文本转化为视频剧情,加上配图、...
最新文章
