 火星网校
火星网校
什么是 Gemini?关于谷歌新AI模型你应该知道的一切
发布时间:2023-12-07 12:33:19 浏览量:134次
Google Gemini是谷歌最新发布的强大人工智能模型,不仅可以理解文本,还能处理图像、视频和音频。作为一种多模态模型,Gemini被描述为能够在数学、物理等领域完成复杂任务,同时能够理解并生成各种编程语言中的高质量代码。

Gemini由Google和其母公司Alphabet共同创建,并作为该公司迄今为止最先进的AI模型发布。Google DeepMind在Gemini的开发中也做出了重要贡献。
Gemini有不同版本吗?
谷歌将Gemini描述为一种灵活的模型,可以在从谷歌数据中心到移动设备的各种平台上运行。为了实现这种可扩展性,Gemini被分为三个版本:Gemini Nano、Gemini Pro和Gemini Ultra。
- Gemini Nano: 设计用于在智能手机上运行,特别是Google Pixel8。它专为在设备上执行需要高效AI处理的任务而构建,无需连接到外部服务器,如在聊天应用中建议回复或总结文本。
- Gemini Pro: 在谷歌的数据中心运行,旨在为公司最新版本的AI聊天机器人Bard提供动力。它能够快速响应并理解复杂的查询。
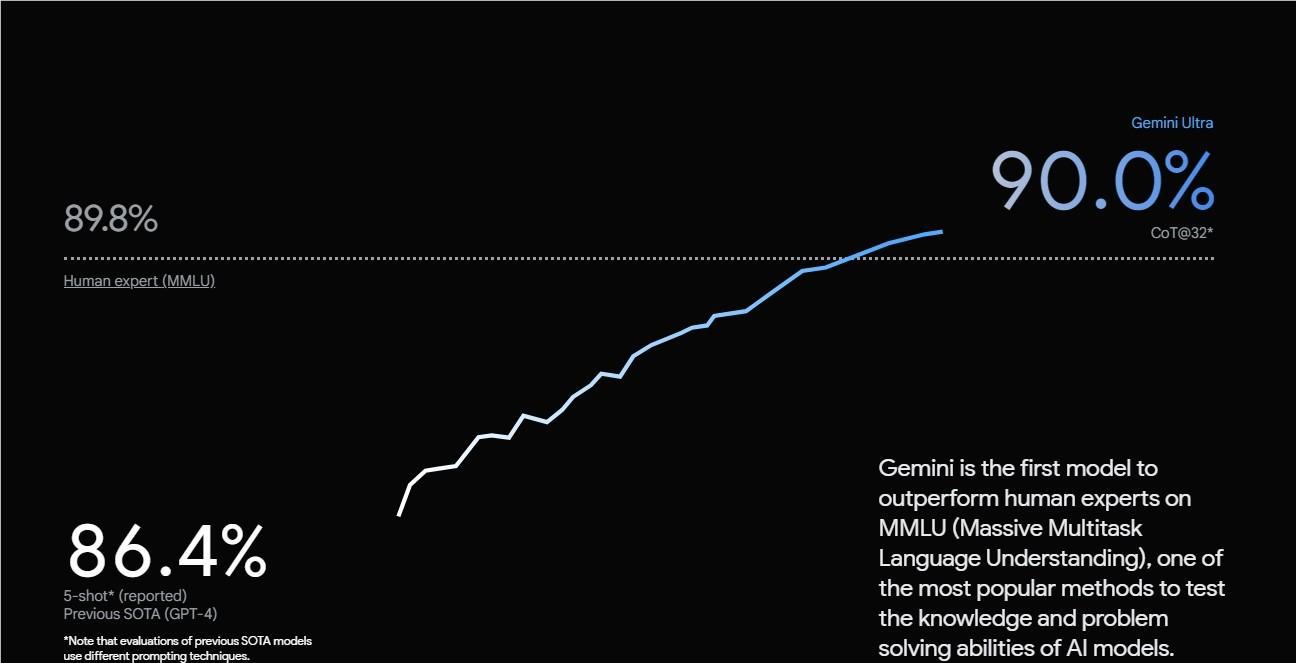
- Gemini Ultra:尽管目前还没有广泛使用,但谷歌将Gemini Ultra描述为其最强大的模型,超过了“在大型语言模型(LLM)研究和开发中使用的32个广泛使用的学术基准中的30个”的当前最先进结果。它专为高度复杂的任务设计,并计划在完成当前测试阶段后发布。
Gemini怎么使用?
Gemini现在可以在Google产品中的Nano和Pro版本上使用,如Pixel8手机和Bard聊天机器人。谷歌计划随着时间的推移将Gemini逐步整合到其搜索、广告、Chrome和其他服务中。
开发人员和企业客户将能够通过Google的AI Studio和Google Cloud Vertex AI中的Gemini API在12月13日开始访问Gemini Pro。Android开发人员将通过AICore在早期预览阶段访问Gemini Nano。
Gemini与GPT-4等其他AI模型有何不同?
谷歌的新Gemini模型似乎是迄今为止最大、最先进的AI模型之一,尽管Ultra模型的发布将最终确定这一点。与当前驱动AI聊天机器人的其他流行模型相比,Gemini因其本地多模态特性而脱颖而出,而其他模型如GPT-4则依赖于插件和集成才能真正实现多模态。
与主要基于文本的模型GPT-4相比,Gemini可以轻松进行本地多模态任务。虽然GPT-4在语言相关任务方面表现出色,如内容创作和复杂文本分析,但它需要依赖OpenAI的插件进行图像分析和访问网络,并依赖DALL-E3和Whisper生成图像和处理音频。
Gemini还比当前可用的其他模型更加产品化。它要么已经集成到公司的生态系统中,要么计划集成,因为它同时为Bard和Pixel8设备提供动力。其他模型,如GPT-4和Meta的Llama,更加服务导向,可用于各种第三方开发人员的应用程序、工具和服务。
Google Gemini的推出标志着谷歌在人工智能领域的进一步创新。其多模态特性使其在处理不同类型的信息时更加灵活,为用户提供了更广泛的应用场景。随着Gemini的逐步整合到谷歌的生态系统中,我们可以期待看到更多令人惊叹的应用和服务。




热门课程推荐

热门资讯
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
2. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
3. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
4. AI显卡绘画排行榜:4090无悬念,最具性价比出人意料
在AI绘图领域,Stable Diffusion的显卡绘图性能备受关注。本文整理了Stable Diffusion显卡的硬件要求和性能表现,以及2023年3月显卡AI绘图效率排行榜和性价比排行榜。欢迎查看最新的AI显卡算力排行榜。
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
7. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
8. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
AI技术的快速发展为各行各业带来了许多创新应用,其中之一就是AI小说生成视频。这种技术利用人工智能算法和语言模型,将文本转化为视频剧情,加上配图、...
最新文章
